
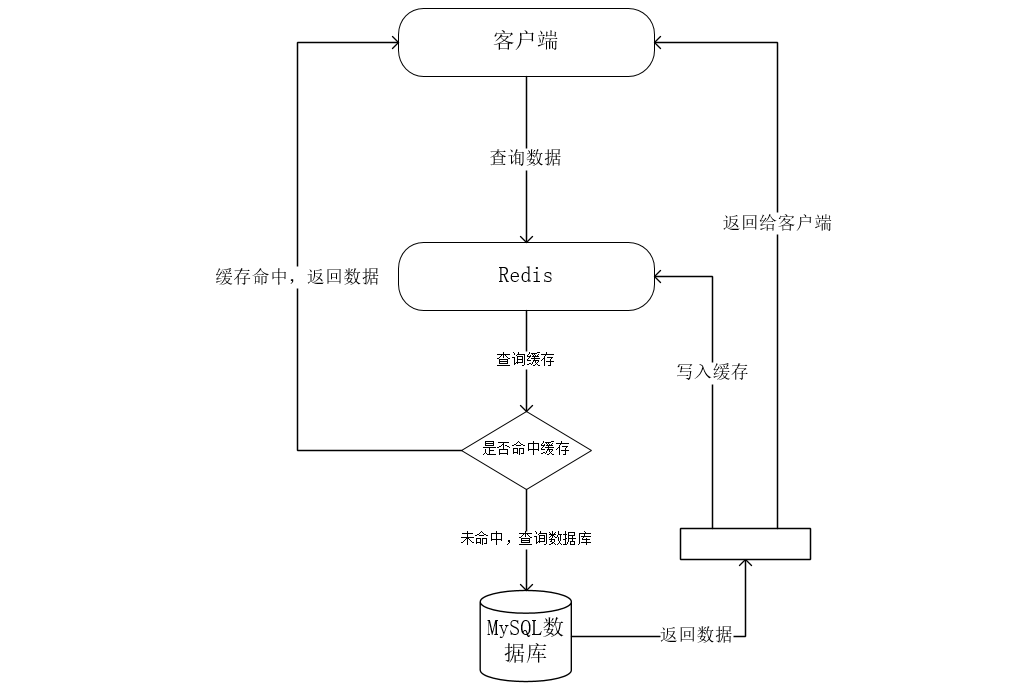
首先我们需要知道正常客户端请求到Redis缓存的工作流程:
正常的情况下,如果 客户端请求的数据有做Redis缓存处理的话,就会直接去访问Redis服务器,查询服务器中是否有这个缓存,如果存在,就直接返回响应给客户端;如果没有命中缓存,就会发送SQL命令去数据库,查询到数据后,把数据缓存到Redis服务器并且返回给客户端,等到下次访问这个数据的时候,就可以直接从Redis服务器中取出数据了。但是也存在一些特殊的情况,发送的请求中,访问的数据不存在,就会透过Redis服务器,直接访问到数据库,会大大加重服务器的负担,这就是缓存穿透。
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,导致这些请求都会透过缓存去访问数据库,最后返回空。我所知道的解决方法有两种,一种是布隆过滤,一种是Redis缓存空对象。
(1)布隆过滤:这种方法占用的内存少,没有多余的key,但是实现复杂,而且其底层是基于hash来实现,就会存在误判的可能(hash冲突问题),且笔者对这种方法的了解没有太过深入,不敢轻易写下解决方案,只作为一种思路的拓展建议。
(2)Redis缓存空对象:这种方法比较好理解,就是当客户端请求的数据不存在的时候,就返回一个空对象,然后再给这个对象设置一个很短的过期时间,这样下次查询该数据的时候,就可以直接从缓存中拿到,从而达到减小数据库的压力的目的。因此,这各方法也是有缺点的,首先会占用缓存空间,如果空缓存过多,会大量占用内存空间,其次就是会导致缓存与数据库数据不一致的问题,即便已经给空缓存设置了较短的过期时间,但是也会导致这段时间内的数据不一致的问题。但这种方法实现简单,且易于维护。
下面是基于第二种方法来实现的解决缓存穿透问题。
1 | /** |
注意:这个方法使用hutool工具包对Bean对象进行转换。CACHE_SHOP_KEY、CACHE_NULL_TTL和CACHE_SHOP_TTL都是自定义的全局关键字,防止后续书写错误。
以上就是解决缓存穿透的一种方法,最后要说的是,如果缓存信息是变化较小的数据或者固定的数据,可以不设置缓存的过期时间。